
In the previous post of this series, we figured out that chromosomes carry genes, and we used genetic linkage and crossing over to start making gene maps of chromosomes. Given enough data on offspring and inherited traits, we could continue this project and make ever more accurate gene maps, identifying the components of chromosomes in ever finer detail. In fact, that’s what went on for some time after Sturtevant’s work in 1913. But we know that this can’t be the end of the story. We know what a gene is now, but we still haven’t talked about a genetic code. How do genes even work? In part 1, we introduced the concept that a gene on a chromosome can ultimately, through a chain of biochemical events, lead to someone having blue eyes:
Specific HERC2 gene in our DNA → rare HERC2 protein → fewer P proteins → less tyrosine → less melanin → bluer eyes
Remember that our whole story (5 parts and counting) involves that first little step: from gene to protein. We know a lot about genes now. We know they’re passed down according to Mendel’s laws of heredity. And we know that the reason for this is because they’re on chromosomes, and chromosomes behave a certain way during fertilization and meiosis. What else do we know? According to our little flowchart above, genes are made of DNA. But wait a second; we never talked about that. We know that DNA is in the nucleus, and that it’s an acid (which is why it’s called DeoxyriboNucleic Acid). We also know that it’s made out of carbon, hydrogen, oxygen, nitrogen, and phosphorus. But that’s about all we’ve discussed so far. So how do we know that genes are made from DNA?
Well, at first, no one did. They knew that genes were on chromosomes and that chromosomes lived in the nuclei of cells, but here’s the thing. Chromosomes are actually made up of DNA packaged with proteins. It’s clear to scientists now that DNA is the bearer of genetic information in the chromosome, but it was originally assumed that proteins did the lion’s share of the genetic work. The only people who seemed to be interested in DNA at the turn of the 20th century were chemists, not biologists. And in fact, a German chemist named Albrecht Kossel took up where Friedrich Miescher had left off with the discovery of DNA. DNA is a complex molecule which falls apart when immersed in a strongly acidic solution. [Side note: this process has a technical name known as acid hydrolysis–“acid” because it occurs in acid and “hydrolysis” because it uses water (Greek hydro) to break apart (Greek lysis) a molecule.] Kossel isolated nucleic acids from yeast using Miescher’s procedure, and then used acid hydrolysis on the nucleic acids. What he got was a big mess. But, being extraordinarily patient and careful, he was able to separate this mess into a few different parts. [How did he do this? Using a method called chromatography, which we’ll talk about in a future HDWKI.] Over the course of about a decade, he found that the nucleic acids were mostly phosphates (which Miescher knew already), a bunch of brown goop, and five distinct molecules, which we now call nucleobases, or just bases for short. He named these bases adenine, guanine, cytosine, thymine, and uracil; we’re more familiar with the letters A, G, C, T, and U. Kossel would win a Nobel Prize in Medicine in 1910 for his discovery.
One of Kossel’s students, a Lithuanian-American named Phoebus Levene, followed the same line of research, discovering gentler methods of hydrolysis than boiling nucleic acids in strong acids for hours on end. First, he subjected the nucleic acid to a weak ammonia solution at elevated temperatures. He separated the soup he got from this step into individual parts using chromatography. He used elemental analysis to show that each part consisted of a phosphate, one of four nucleobases (A, G, C, or U), and a chemical with the formula C5H10O5. After this step, he went ahead and did the full throttle hydrolysis with boiling sulfuric acid and picric acid (an explosive related to TNT: when fireworks whistle loudly, you’re hearing picric acid burning). This time, he was able to separate the nucleobase from the rest of the junk. This result told him that the nucleobase was attached through the C5H10O5 compound to the phosphate. [An interesting note about C5H10O5. It follows a pattern that immediately jumps out to a chemist: It has the form Cn(H2O)n. Since its formula is that of carbon + water, you could call it “hydrated carbon.” In fact, that’s exactly what we call it: a carbohydrate, better known by its more common chemical name–sugar.] He didn’t know the importance of this at the time, but he had just determined the first clue to the structure of DNA. If DNA is a double helix, then Levene figured out the basic pattern of one of the helices. Here’s a visual summary of what he discovered:
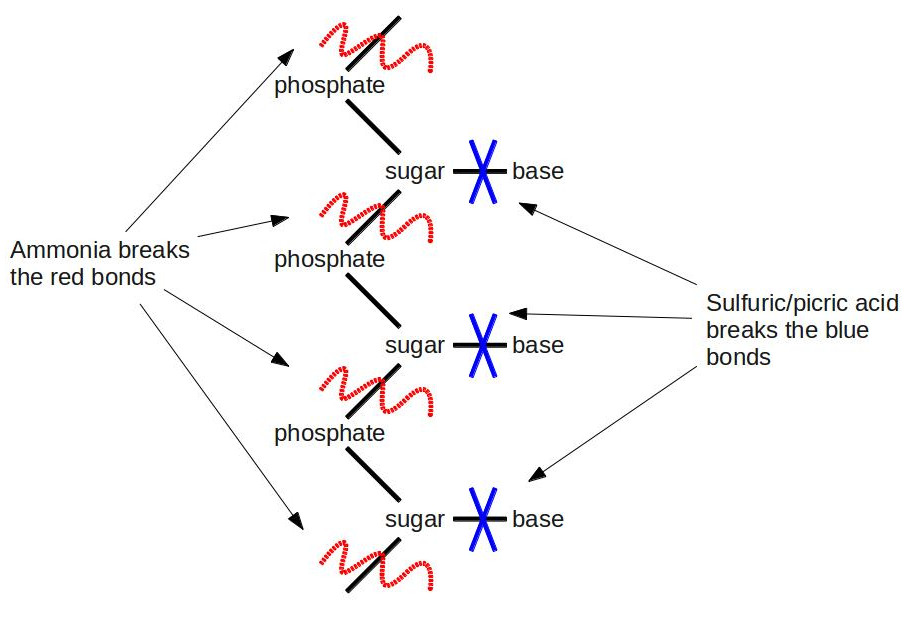 Some biochemists are probably groaning right now. They’re saying: “Levene’s experiments don’t deal with DNA at all. The bases in DNA are A, G, C, and T, not U. U (for uracil) is only present in RNA.” Some astute biochemists might jump on the bandwagon and say: “Hey yeah, and C5H10O5 is the formula for the sugar ribose, which is the ‘R’ in RNA; not deoxyribose, which is the ‘D’ in DNA, and which has the formula C5H10O4 (it’s minus one oxygen; hence the name deoxyribose).” Some of the non-biochemists are scratching their heads: “What the heck is RNA?” Trust me, RNA will become a main character a little later in our story, but we’ll put off introducing it for now. Suffice it to say that the biochemists are technically right. Levene was observing RNA. But in the 1910’s, there wasn’t yet a clear distinction between DNA and RNA. It was all just lumped under the generic term “nucleic acid.” Some scientists had begun to observe slight differences between DNA and RNA, but to confound matters further, the sources of the different nucleic acids led them to believe that DNA was only found in plants, and RNA was only in animals. We know today that DNA and RNA are both found in plants and animals, but it was quite a confusing situation at the time.
Some biochemists are probably groaning right now. They’re saying: “Levene’s experiments don’t deal with DNA at all. The bases in DNA are A, G, C, and T, not U. U (for uracil) is only present in RNA.” Some astute biochemists might jump on the bandwagon and say: “Hey yeah, and C5H10O5 is the formula for the sugar ribose, which is the ‘R’ in RNA; not deoxyribose, which is the ‘D’ in DNA, and which has the formula C5H10O4 (it’s minus one oxygen; hence the name deoxyribose).” Some of the non-biochemists are scratching their heads: “What the heck is RNA?” Trust me, RNA will become a main character a little later in our story, but we’ll put off introducing it for now. Suffice it to say that the biochemists are technically right. Levene was observing RNA. But in the 1910’s, there wasn’t yet a clear distinction between DNA and RNA. It was all just lumped under the generic term “nucleic acid.” Some scientists had begun to observe slight differences between DNA and RNA, but to confound matters further, the sources of the different nucleic acids led them to believe that DNA was only found in plants, and RNA was only in animals. We know today that DNA and RNA are both found in plants and animals, but it was quite a confusing situation at the time.
The biochemistry of DNA took a long time to figure out (chemists were still hacking away at it up until the 40’s and 50’s), but the discoveries of Kossel and Levene actually set back progress in genetics, in a way. See, DNA and RNA only have 5 bases between them, compared with the seeming infinite complexity of proteins. This convinced most scientists, including Levene himself, that there was no way DNA could store all the genetic information of an organism. It just had to be proteins. But of course, we know now that DNA does, in fact, carry the genetic code. So what happened to change everyone’s mind? It all started with a remarkable, albeit seemingly unrelated, experiment.
In 1928, Frederick Griffith published the results of a study of pneumonia patients in England, where he was a medical officer for the Ministry of Health. Pneumococcus (pronounced new-mo-cock-us), the bacterium that causes pneumonia, comes in several different varieties. Griffith collected specimens from the patients and determined which variety each patient had by looking at what happened when the specimens were exposed to certain kinds of blood serum. This was a process discovered by Fred Neufeld: you inject a rabbit with a little bit of a specific strain of pneumonia, then wait a few days. Then you take some of the rabbit’s blood and separate out the blood cells from the serum. The serum (now called rabbit antiserum) contains substances that react with that specific strain of pneumonia, causing those bacteria–but no other bacteria–to swell under a microscope. So Griffith took each patient’s sample and reacted it with various rabbit antisera (plural of antiserum) to see which ones made the bacteria in the samples swell up. He would then inject a mouse with the strain to confirm the diagnosis of pneumonia (and usually kill the mouse in the process).
Griffith’s experiment was supposed to be a routine headcount to see what different types of pneumonia were floating around in London in the mid 1920’s. But Griffith noticed something odd: sometimes he’d get a sample that he determined to be Type I pneumonia, but after it was injected into the mouse, it would be Type IV pneumonia. In fact, the types of pneumonia a patient had seemed to interchange over time. But this shape-shifting wasn’t what troubled Griffith the most. The pneumococcus bacterium comes with two different outer coatings. The outer coating determined whether the body’s immune system would attack the bacteria or not. If the bacterium’s coating was smooth (Griffith called this variety “S”), it resisted attacks by the immune system and made its victims very sick with pneumonia in the process. If the coating was rough-looking (Griffith called it “R”), the immune system could wipe the bacterium out and you wouldn’t even know you had it. But Griffith noticed in one of his samples that R bacteria had also begun to make people very sick. A new strain of pneumonia in the era before penicillin was very dangerous, so Griffith set out to figure out what was going on.
Griffith thought that maybe what was happening was that the R form might be picking up some genetic information from the S form somehow. He had observed that if R bacteria were exposed to S bacteria, the R form could make mice sick, even after the S bacteria were long gone. His hypothesis was that when R bacteria were injected into a mouse, some piece of the S bacteria remains and gets incorporated into the R bacteria somehow. So when the mouse’s immune system kills off the nonlethal R bacteria, what’s left over is a sort of R-S Frankenstein bacterium that is just as deadly as pure S bacteria.
Griffith tested his hypothesis by doing 3 experiments. In the first, he just showed that “virgin” R bacteria (that had never been exposed to S bacteria) didn’t make mice sick. In the second, he took pure S bacteria and steamed them with boiling water, killing them. He then injected dead S bacteria into mice and showed that the mice didn’t get sick. In the third experiment, he mixed virgin R bacteria with heat-killed S bacteria and injected this cocktail into mice. The mice died, and the bacteria taken from them were all living S-type bacteria. You know what? This is easier with a picture, shamelessly stolen from Wikipedia:

Take a second to think about how crazy this is: you mixed living R-type bacteria with dead S-type bacteria, and you got back living S-type bacteria. I’m pretty sure Griffith’s experiment is the inspiration for the entire genre of zombie movies. When it was published, his study immediately found detractors. Most scientists assumed he’d done something wrong or hadn’t been sufficiently careful with cross-contamination of experiments. But Griffith was a remarkably meticulous scientist, and others quickly repeated his experiments with similar results. It seemed clear that Griffith had found a way for bacteria to transfer genetic material–what he called the transforming principle–between one another. But what was this transforming principle? What was it made out of?
Ostwald Avery, Colin MacLeod, and Maclyn McCarty decided they were going to find out. They set about attempting to extract and purify the transforming principle. First, they grew S bacteria and killed them with steam. Then they removed the outer layers of the bacteria in several steps by washing with different solutions, being sure after each step to check that the remaining material still caused R-type bacteria to transform into S-type. (Their washing procedure was really just an updated version of Miescher’s procedure to isolate DNA.) What was remarkable to them was that, even when the proteins were removed, the transforming principle was still present. This meant that proteins couldn’t be the carriers of genetic information. So they took the remaining material and did…what else?…elemental analysis on it. They found that the proportion of elements in the transforming principle was identical to the proportion of elements in DNA, including traces of phosphorus.
From here, their experiments were straightforward (although not simple). In a nutshell, they analyzed the transforming principle with a series of enzymes. They showed that enzymes that destroy proteins had no effect on the substance’s ability to change R bacteria to S bacteria. They also showed that enzymes that destroyed RNA had no effect either. It was only when they used enzymes that destroy DNA that the transforming principle could no longer transform. This was the result that convinced Avery, MacLeod, and McCarty that the transforming principle, and hence all genetic information, was carried by DNA.
The Avery-MacLeod-McCarty experiment was published in 1944, and its results were hotly debated. By 1952, most of the scientific community had been convinced that DNA was responsible for storing and transmitting genetic information, but there were still a few holdouts. They clung to the idea that these experiments were contaminated with proteins, and that proteins were doing the bulk of the genetic work. The final nail in the coffin for the protein genetic theory was a virus study by Alfred Hershey and Martha Chase. Viruses are basically little packets with an outer protein shell surrounding a DNA (or RNA) interior. They’re interesting because they don’t have the biological tools necessary to reproduce on their own. So they invade other cells and use those cells’ machinery to build replicas of themselves. In order to do this, they inject genetic material into the cells, and the cells use the genetic material as instructions to assemble new viruses. Hershey and Chase were able to show that a special kind of virus that invades bacterial cells–called a bacteriophage–only injects DNA into the bacteria, not proteins. This meant that it had to be DNA, not proteins, that carried genetic material, because the proteins of the virus didn’t even get into the cell.
How did Hershey and Chase show this? They used radioactivity. (I swear, sometimes the sheer magnitude of crazy in the biology community blows me away.) Remember how Friedrich Miescher knew that DNA wasn’t a protein? Because it contained phosphorus and not sulfur, whereas proteins contain sulfur but not phosphorus? Maybe something to refresh your memory? Well, it just so happens that certain varieties of phosphorus and sulfur are radioactive. So Hershey and Chase took some radioactive sulfur and bred viruses in its presence. The viruses incorporated the radioactive sulfur into their proteins. Then the pair did the same with phosphorus and a different batch of viruses. These viruses incorporated the radioactive phosphorus into their DNA. Then they let each of the viruses invade different bacteria. Using a centrifuge, they could separate the insides of the bacteria from the outsides. If proteins were the carriers of genetic material, then Hershey and Chase would have seen radioactive sulfur on the inside of the bacteria. But when they let the viruses with radioactive sulfur invade the bacteria, they only found radioactivity on the outsides of the bacteria, meaning that the sulfur–and therefore the proteins–couldn’t have gotten inside the bacteria. When they let the viruses with radioactive phosphorus invade, they only found radioactivity on the insides of the bacteria, meaning that phosphorus–and therefore the DNA–had gotten into the bacteria. This proved what Avery, MacLeod, and McCarty had anticipated: that DNA is the carrier of genetic information. And that was the end of the protein genetic theory.
It’s hard to gauge the sentiments of the scientific community sometimes, and as a result, it’s unclear when exactly the tipping point was for DNA becoming the main focus of genetics. Most people think it happened sometime between the Avery-MacLeod-McCarty experiment in 1944 and the Hershey-Chase experiment in 1952. Hershey and Chase themselves were very careful not to explicitly state that DNA was the universal genetic carrier, but it’s clear that after their experiment, virtually everyone now recognized the immense importance of DNA. This included two groups of young scientists: one, at King’s College London, consisting of Maurice Wilkins and Rosalind Franklin, and another, at Cambridge, consisting of James Watson and Francis Crick. We’ll talk about these four next time.
References
A biography of Albrecht Kossel can be found here:
Levene’s paper describing the chemical structure of nucleic acid:
Griffith’s paper on the transforming principle:
The paper on the Avery-MacLeod-McCarty experiment:
Hershey and Chase’s paper is here: