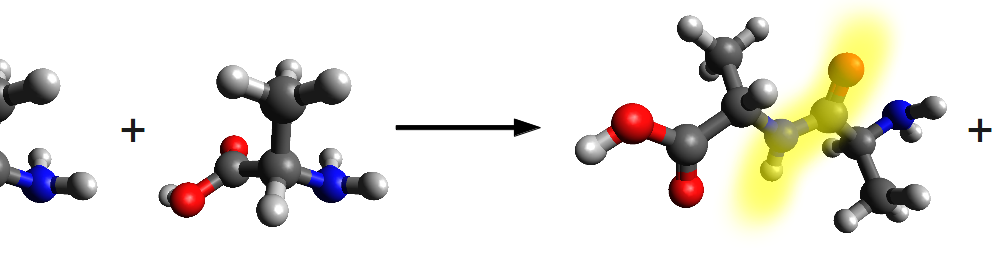
Reaction of two alanine molecules. The peptide bond is highlighted in yellow.
In the previous post in our series on the genetic code, we chronicled the adventures of a number of chemists, biologists, and even an epidemiologist as they battled their way to a fundamental truth about genes. Spoiler alert for those who haven’t read it yet: genes are made of DNA. It seems like such a basic fact now; most middle-schoolers can recite it. But keep in mind that nearly a century separates Friedrich Miescher’s discovery of DNA from the widespread acceptance of DNA as the genetic material.
Up to this point, we’ve been looking pretty much exclusively at the relationship between genetic information and DNA. But our ultimate goal is to explain how the genetic information in our DNA encodes the proteins that determine the structures and day-to-day operations of our bodies. We want to crack the genetic code, but how do we even know there’s a code in the first place? How do we know that the genes in our DNA contain instructions for building proteins? To answer this, we need a little bit of background.
What is a protein?
When most people think of proteins, they probably think of a tasty chocolate(-flavored) shake after a workout. Or maybe meat or eggs. The way we typically talk about proteins suggests that they have something to do with the structural makeup of our bodies. This is true; for instance, collagen is a well-known protein that makes up roughly a quarter of our dry mass (that is to say, our weight if the water in our bodies is excluded). Think of that: a single type of protein makes up around 25% of our bodies. In fact, this site suggests that proteins make up 75% of our dry mass altogether (the remaining 25% is mostly bone and fat–obviously these numbers are variable depending on how “big-boned” you are).
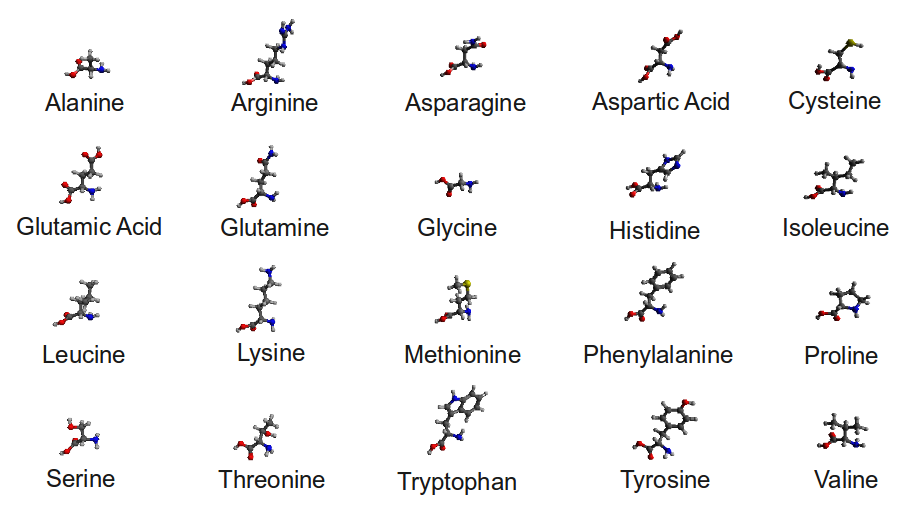
We’ve already talked about how proteins are chemically different from DNA: proteins have sulfur in them, while DNA has phosphorus. But in fact, it’s more complicated than that. By the mid-1800’s a number of proteins had been identified, including albumin from egg whites, pepsin from pig stomachs, casein from cheese, and gluten from wheat. In 1838, a German by the name of Gerardus Johannes Mulder did elemental analysis on several of the proteins known at the time, and discovered that they all had roughly the same formula: C400H620N100O120P1S1 (notice that he found phosphorus in his proteins: this was likely due to contamination of his protein samples with nucleic acids or phosphates from other sources). Mulder boldly proposed that all proteins were actually the same molecule. Unfortunately, this didn’t turn out to be true. However, Mulder did manage to identify another important feature of proteins, using acid hydrolysis, an experiment familiar to anyone who’s read part 5 of this series. When Mulder boiled proteins in acid, they broke down into small molecules, a few of which he was able to isolate and identify. Over the next century, many scientists worked to enumerate these molecules and figure out their chemistry. Today we call these protein building blocks amino acids, and we identify 20 common ones and several significantly less common ones.
The 20 common amino acids. Carbon atoms are gray, hydrogens are white, nitrogens are blue, oxygens are red, and sulfurs are yellow.
As you can see from the picture, there are big differences among the amino acids. This variabililty caused a huge amount of confusion among chemists in the 1800’s. The methods that they used to determine molecular structure were far less advanced than the ones modern chemists use today, and in fact the structures of some of the amino acids took decades to finally nail down [How exactly did chemists figured out these structures? Stay tuned for a future HDWKI]. But I’ve also tried to arrange the pictures of the amino acids in a way that makes the similarities among them more clear. Here’s a closeup of alanine as an example:
I’ve highlighted a few important features. There’s a central carbon atom, off of which hangs a hydrogen atom in front. Then, to the right is a nitrogen attached to two hydrogens. This NH2 group is called an “amine” group. To the left of the central carbon is another carbon attached to two oxygens, one of which has a hydrogen attached to it. This COOH group is called a “carboxylic acid.” All amino acids have an amine group and a carboxylic acid group (that’s where the name amino acid comes from), as well as the central carbon and hydrogen. Finally, above the central carbon atom, each amino acid has a different group of atoms. This is called the “radical” group, or R group for short, and it’s the R group that determines which amino acid you’re dealing with.
Shredding proteins into their constituent amino acids was a favorite pastime of 19th century chemists the world over, but it wasn’t until 1902 that someone considered the reverse question: if we start from amino acids, how do we put proteins together? This question was answered by Emil Fischer (the second person ever to win the Nobel Prize in Chemistry). He saw that a carboxylic acid could combine with an amine to form a strong carbon-nitrogen bond known as a peptide bond. [Side note–The carboxylic acid loses an oxygen and a hydrogen, and the amine loses a hydrogen, and these 3 atoms combine to give a water molecule. In fact this type of reaction is known as a dehydration reaction, because water is lost from the combination of the molecules.]
Reaction of two alanine molecules. The peptide bond is highlighted in yellow.
What’s more, Fischer used some really clever chemistry to make peptide bonds between amino acids. Using these techniques, he was able to string individual amino acids into long chains. This observation led to the hypothesis that proteins are a long string of amino acids linked together by peptide bonds.
The discovery that proteins are chains of amino acids would have been monumental on its own, but its importance was magnified by another discovery that had taken place just 5 years earlier, by a scientist named Eduard Buchner. Buchner was interested in the problem of fermentation, the chemical process that creates alcohol in beer and wine. It has been known since antiquity that, in order to ferment wine or beer, you have to add yeast. Buchner knew that yeast was a single-celled organism, and that it reacted with the sugar in grapes/barley/hops to make alcohol. He was determined to figure out how yeast was able to produce alcohol from sugars. At the time, it was believed that yeast had to be living in order for the fermentation process to work. Buchner, channeling his inner three-year-old, decided to take a bunch of yeast and mutilate the crap out of it. He ground the yeast up with sand and then smashed it in a hydraulic press with a force several hundred times more than the pressure in your tires. After repeating this process a couple of times, he obtained a yellow liquid consisting mainly of water and proteins, but importantly, there were no living yeast cells left. He then showed that this “press juice,” as he called it, could generate carbon dioxide when sugar was added to it, a clear sign of fermentation (carbon dioxide is what makes beer and champagne bubbly). He concluded that it was the proteins in yeast cells, and not the cells themselves, that were responsible for fermentation.
Buchner’s work might not sound all that impressive, but it won him a Nobel Prize in 1907, and for good reason. You see, in the early days of biochemistry (circa mid-1800s), there were two competing theories. The first, called vitalism, held that organisms had to be alive to carry out complicated biochemical processes. The second theory, known as the enzyme theory, said that chemical processes in cells were controlled by special proteins called enzymes, and that the cells didn’t even have to be alive in order for these enzymes to work. Buchner settled the debate between the vitalists and the enzymists once and for all. In doing so, he discovered an even more important truth. In addition to being a key structural building block in our bodies, proteins carry out most of the important chemical processes in our cells through their actions as enzymes. This means that our strengths, weaknesses, appearances, and to some extent even our personalities are determined by proteins. In short, proteins determine most of what makes us, us.The connection between proteins and DNA
Between Fischer and Buchner (and plenty of other scientists who corroborated and extended their work), we have established two facts:
1) Proteins are made of countless different combinations of 20+ amino acids, strung together like pearls on a string.
2) Proteins govern most of the biochemical actions of living organisms.
Given these two facts, it’s no wonder that scientists believed proteins were the carriers of genetic information. But we know now that genetic information is in fact carried by DNA. And knowing what we know about proteins and DNA now, it might make sense to say that DNA and proteins are related somehow. Think about it:
1) Proteins control the chemical and biological makeup of an organism, and
2) DNA makes up genes which also somehow control the makeup of an organism.
So it must be the case that the information carried by DNA at some point gets transferred over to proteins. This was straightforward and reasonable hypothesis, but one that turned out to be devilishly difficult to prove.
In fact, the hypothesis can be proven in two steps. First, we must show that genes come from DNA (something we proved last time). Second, and equally tricky, we must show that proteins come from genes. The solution to this second problem came as a result of a series of brilliant experiments by George Beadle and Edward Tatum, published in the early 1940’s.
Beadle had spent some time at Caltech working with Thomas Hunt Morgan in his fruit fly lab. Apparently coming to his senses, Beadle questioned what he was doing with his life, and decided to abandon his intensive, meticulous, and tedious research on flies to follow his true calling instead: performing intensive, meticulous, and tedious research on bread mold. He later became a professor of biology at Stanford, where he would do his most famous work with Tatum, a Stanford biochemist.
Beadle and Tatum designed their experiment around what I’ll call the “Jurassic Park principle.” For those of you who maybe need a 90’s pop culture refresher, or worse, are unfamiliar with the book/movie (blasphemy!), the dinosaurs in the park are genetically engineered with a defect that prevents their bodies from producing a necessary amino acid (I believe it was lysine). Thus the amino acid has to be introduced artificially into their diets. This step was taken deliberately by the biologists at Jurassic Park so that, if there were ever a catastrophic breach of security and the dinosaurs got out of their pens, they would die without their daily dose of necessary amino acid.
Beadle and Tatum took the same approach to bread mold. They used x-rays to introduce genetic defects into the bread mold. Their specific goal was to see whether mutations in the mold’s genes caused changes in the actual enzymes of the mold. If this were the case, then mutant bread molds (most disgusting superheroes ever) would have certain changes in biochemistry which should affect their normal cellular processes. In order to show that biochemical changes had taken place due to genetic mutations, Beadle and Tatum examined bread molds that had been mutated so that they could not carry out some necessary biochemical process. For example, in one case, a mutant strain of mold could not synthesize vitamin B6, and thus would die unless the vitamin were introduced into its environment by the researchers. And since the mold reproduces sexually, Beadle and Tatum showed that the inability to synthesize vitamin B6 was inheritable, following Mendel’s rules of heredity. This research, along with subsequent work by a number of scientists, proved two things:
1) Genes (the units of heredity) are responsible for the production of enzymes, and therefore are in control of the biochemical reactions in living organisms.
2) In addition, it seemed that each gene was responsible for one–and only one–enzyme.
As luck would have it, Beadle and Tatum were doing their work at roughly the same time that Avery, MacLeod, and McCarty were performing their experiments showing that genes were carried on DNA. Scientists now were able to connect the dots and see that proteins are controlled by genes, which themselves are constructed from DNA. A fully modern picture of biochemistry was coming into focus. But the question still remained: how exactly does the information contained in DNA get translated into proteins? In other words, scientists now knew of the existenceof a genetic code; it only remained for them to find it and crack it. We’ll start laying the groundwork for that story in part 7.
References
This paper and references therein give pretty good information about Mulder’s early studies of proteins:
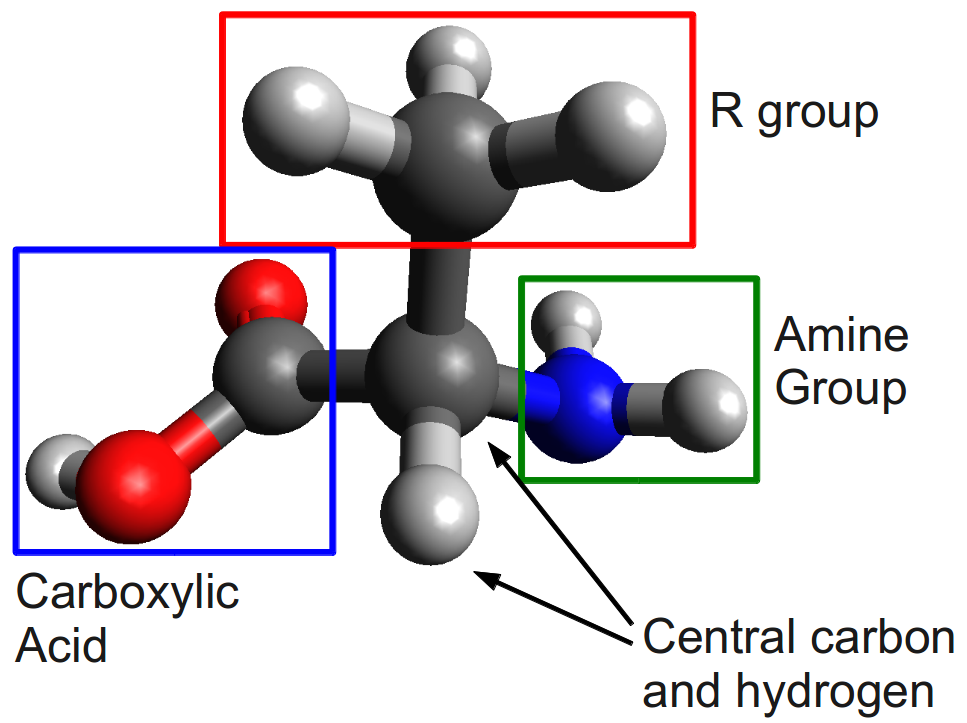 I’ve highlighted a few important features. There’s a central carbon atom, off of which hangs a hydrogen atom in front. Then, to the right is a nitrogen attached to two hydrogens. This NH2 group is called an “amine” group. To the left of the central carbon is another carbon attached to two oxygens, one of which has a hydrogen attached to it. This COOH group is called a “carboxylic acid.” All amino acids have an amine group and a carboxylic acid group (that’s where the name amino acid comes from), as well as the central carbon and hydrogen. Finally, above the central carbon atom, each amino acid has a different group of atoms. This is called the “radical” group, or R group for short, and it’s the R group that determines which amino acid you’re dealing with.
Shredding proteins into their constituent amino acids was a favorite pastime of 19th century chemists the world over, but it wasn’t until 1902 that someone considered the reverse question: if we start from amino acids, how do we put proteins together? This question was answered by Emil Fischer (the second person ever to win the Nobel Prize in Chemistry). He saw that a carboxylic acid could combine with an amine to form a strong carbon-nitrogen bond known as a peptide bond. [Side note–The carboxylic acid loses an oxygen and a hydrogen, and the amine loses a hydrogen, and these 3 atoms combine to give a water molecule. In fact this type of reaction is known as a dehydration reaction, because water is lost from the combination of the molecules.]
I’ve highlighted a few important features. There’s a central carbon atom, off of which hangs a hydrogen atom in front. Then, to the right is a nitrogen attached to two hydrogens. This NH2 group is called an “amine” group. To the left of the central carbon is another carbon attached to two oxygens, one of which has a hydrogen attached to it. This COOH group is called a “carboxylic acid.” All amino acids have an amine group and a carboxylic acid group (that’s where the name amino acid comes from), as well as the central carbon and hydrogen. Finally, above the central carbon atom, each amino acid has a different group of atoms. This is called the “radical” group, or R group for short, and it’s the R group that determines which amino acid you’re dealing with.
Shredding proteins into their constituent amino acids was a favorite pastime of 19th century chemists the world over, but it wasn’t until 1902 that someone considered the reverse question: if we start from amino acids, how do we put proteins together? This question was answered by Emil Fischer (the second person ever to win the Nobel Prize in Chemistry). He saw that a carboxylic acid could combine with an amine to form a strong carbon-nitrogen bond known as a peptide bond. [Side note–The carboxylic acid loses an oxygen and a hydrogen, and the amine loses a hydrogen, and these 3 atoms combine to give a water molecule. In fact this type of reaction is known as a dehydration reaction, because water is lost from the combination of the molecules.]

One reply on “How do we know the genetic code? (Part 6)”
Hi, when will the part 7 come out? I’m so interested!